
spark optimizations
optimizations can be at application code level or at cluster level, here we are looking more at cluster level optimizations
application code level
few of the things which can be configured/used, when doing application code are:
- partitiong
- bucketing
- cache/persist
- avoid/minimize shuffling
- join optimizations
- optimized file format
- using reduceByKey instead of groupByKey
cluster configuration
to understand the cluster level configuration, lets say we have 10 node cluster (worker) with 16 core & 64GB ram each.
- executor, is a container which holds some core & memory
- one node can have more than one executor
- executor/container/jvm is same in this context
thin executor
- create more executors with each executor having minimum possible resources
- one core will always be required by node for daemon threads and one gb memory will be required for operating system
- for above example, 15 executors can be created with one core each
cons:
- we loose on mutithreading as each executor get one core
- for broadcast, n copies need to be done for n executors
fat executor
- give maximum possible resources
- one core will be always be required by node for daemon threads and one gb memory will be required for operating system
- for above example, all 15 cores in one executor
cons:
- if executor hold more than 5 core then hdfs throughput suffers
- if executor holds large memory, garbage collection (removing unused objects from memory) takes lot of time
balanced approach
- for exmple above as mentioned, one core for daemon threads and one gb for operating system. So we left with 15 cores and 63GB ram. We want mutithreading and hdfs through be optimal, hence we can use 5 cores in executor
- we can have 3 executors with 5 cores & 21GB ram
- out of 21GB ram, some of it is part of overhead(off heap memory aka raw memory)
- max of 348MB/7% of executor memory is off heap memory, it is overhead not part of container, so here approx 1.5GB is overhead, hence around 19GB will be avaialble for each executor
- 3 executor per node in 10 node cluster we will have 30 executors
- one executor out of 30 will be taken up by yarn, total 29 executor for application
- tasks in executor is equal to number of cores, so 5 tasks can run parallelly in our case in each executor
on heap memory
- local to the executor
- jvm manages and does the garbage collection
off heap memory
- used for some optimizations as garbage collection is not required
- but need to do memory management programmatically to use off heap
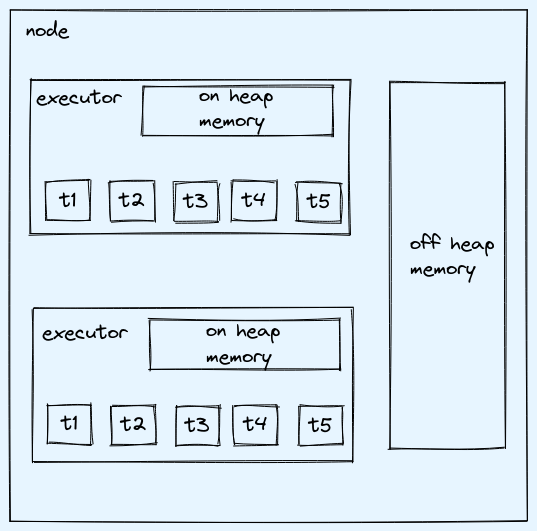
understanding running on cluster
- in hadoop setup like cloudera we have edge nodes which we can connect to
- with edge node we can do some interactive querying and if setting is to
localthen it will have just one executor acting as driver & executor both - we can set master
yarnto run it on full cluster - use
spark-shellto runscalacode - to run in local mode:
spark-shell --master local[*] - to run on cluster:
spark-shell --master yarn
ways to allocate resources
dynamic
spark.dynamicAllocation.enabledis set to true, can be checked in environment tab in spark ui- few more properties it require
- for long running jobs if it has to work on different number of tasks in different stages then dynamic is good
#app will start with initial number of executors as per this property
spark.dynamicAllocation.initialExecutors
#app can use maximum number of executors as per this property
spark.dynamicAllocation.maxExecutors
#app can use minimum number of executors as per this property
spark.dynamicAllocation.minExecutors
#app can use free number of executors as per this property
spark.dynamicAllocation.executorIdleTimeout
static
- to use it need to disable dynamic allocation
- we cannot ask for more memory then set max in resource negotiator (take in consideration off heap as well 7%)
- same for core
spark-shell --conf spark.dynamicAllocation.enabled=false --master yarn --num-executors 20 --executor-cores 2 --executor-memory 2G
example application
//lets say data(coloun delimited) we have is: state, date
//lets say size of file is 10GB
val rdd1 = sc.textFile("/path/to/file")
val rdd2 = rdd1.map(x => (x.split(":")(0), x.split(":")(1)))
val rdd3 = rdd2.groupByKey
val rdd4 = rdd3.map(x => (x._1, x._2.size))
rdd4.collect
- whatever memory is set, 300MB goes for some overhead
- remaining is divided in two parts: storage & execution memory- 60 percent of remaining, additional buffer- 40 percent of remaining
- partitions are decided by number of blocks of data, 10GB file will have 10*1024/128 = 80 partitions
- tasks will be equal to number of partitions, per stage it will be 80 tasks
- executors can execute multiple tasks one after other
- multiple executor cannot work on same partition
- if executor has n core then only n task can be performed at a time
- total parrellism = number of executors * number of cores in each executor
- if groupByKey used, shuffle will happen and if we have 2 distinct keys then no matter cluster size it will have to be processed by only 2 executors
- in case above (2 distinct keys) if input file is 10GB then one executor has to process atleast 5GB and at max ~10GB
- and if memory is not enough on executor it will fail with OOM
- salting can be used to solve such issue, so as less cardinality column can have more distinct keys to have filled partitions to run in parallel
salting
- above problem where we have only few partitions to process like only 2 partitions then we underutilize cluster, and it will take more time.
- we can increase container size but still only 2 executors will work, so another options is to use salting
- add random number to the key and increase cardinality(distinct keys) to get parellelism
val random = new scala.util.Random
val start = 1
val end = 60
val rdd1 = sc.textFile("/path/to/file")
val rdd2 = rdd1.map(x => {
var num = start + random.nextInt( (end - start) + 1 )
(x.split(":")(0) + num,x.split(":")(1))
})
val rdd3 = rdd2.groupByKey
val rdd4 = rdd3.map(x => (x._1 , x._2.size))
rdd4.cache
val rdd5 = rdd4.map(x => {
if(x._1.substring(0,4)=="WARN")
("WARN",x._2)
else
("ERROR",x._2)
})
val rdd6 = rdd5.reduceByKey(_+_)
rdd6.collect.foreach(println)
memory
- execution memory: memory required for computations like shuffle, join, sort, agg
- storage memory: used for cache
- both share common region
- when no execution running then storage can acquire all memory and vice versa
- execution may evict storage if necessary, it happens until some threshold only
- storage cannot evict execution memory
- max of 384MB or 10% (depends on admin previous case above we used 7%) spark executor memory (memory overhead): off heap memory for vm overhead
- execution (shuffle, join, sort, agg) & storage memory (for cache, broadcast)
- user memory (for data structure, safegaud against OOM)
- reserved memory (storage for running executor): 300MB
example: 4GB we assign to executor then
- total: 4096MB
- off heap: 10% of 4GB is 409MB, so 4096+409MB should be avaialble to make executor run
- reserved: 300MB
- execution&storage: 60% of (total-reserved) = 3796MB * .6 = 2277MB
- user memory: 40% of (total-reserved) = 3796MB * .4 = 1518MB
- storage memory is around 50% of storage&execution, so we can have around 2277MB * .5 = 1138MB for cache & broadcast
important internals
- when working with rdd then after shuffle number of partitions remain same but in dataframe/dataset after shuffle it will create default number of partitions (200), which can be changed
- if we use take/collect action then driver should have that much memory to handle data else it will fail with OOM, it can be configured while invoking spark shell via parameter
--driver-memory
join
we should aim to avoid/less shuffling & increase parallelism to process faster for joins we can have either:
- one large table and other small then should use broadcast for small
- both small table, spark not the way
- both tables large then filter & aggregations of data as much as possible before join
- at max how many parallel task can run = min(number of partitions set, distinct keys, total cores)
- skew partitions, this happens due to less distinct keys then we can solve using salting
- bucketing & sorting on join column on both the tables can make join faster, this is same as SMB (Sort Merge Bucket) join
example:
if we have 250 cores in cluster, default after shuffling 200 partitions will be there, and we have more than 250 partitions to process initially, in this case:
- 50 cores left will be wasted
- if distinct keys are only 100 then other 150 will be wasted
sort aggregate vs hash aggregate
val orderDF = spark.read.format("csv").option("inferSchema",true).option("header",true).option("path","orders.csv").load
orderDF.createOrReplaceTempView("orders")
//long running
spark.sql("select order_customer_id, date_format(order_date, 'MMMM') orderdt, count(1) cnt,first(date_format(order_date,'M')) monthnum from orders group by order_customer_id, orderdt order by cast(monthnum as int)").show
//plan, it uses sort aggregate
spark.sql("select order_customer_id, date_format(order_date, 'MMMM') orderdt, count(1) cnt,first(date_format(order_date,'M')) monthnum from orders group by order_customer_id, orderdt order by cast(monthnum as int)").explain
//optimized query
spark.sql("select order_customer_id, date_format(order_date, 'MMMM') orderdt, count(1) cnt,first(cast(date_format(order_date,'M') as int)) monthnum from orders group byorder_customer_id, orderdt order by monthnum").show
//plan, it uses hash aggregate
spark.sql("select order_customer_id, date_format(order_date, 'MMMM') orderdt, count(1) cnt,first(cast(date_format(order_date,'M') as int)) monthnum from orders group byorder_customer_id, orderdt order by monthnum").explain
sort aggregate
- first the data is sorted based on the grouping columns, which takes time
- for sorting complexity will be O(nlogn)
- if data is doubled then time it takes will be more than double
hash aggregate
- no sorting is required, as same value will be overwritten for the unique key as aggregate
firstis used - additional memory is required to have the hashtable kind of structure
- if distinct keys are not much then should always go for hash aggregates
- complexity will be O(n)
- hash table kind of structure is not a part of container, rather this additional memory is grabbed as part of off heap memory, not the part of your jvm
why in query 1 it took sort aggregate
month number is string, which is immutable. when we are using hash aggregate we should have mutable types in the values
catalyst optimizer
- structured apis (dataframe/dataset/sparksql) performs better than rdds
- optimizes execution plan for structured apis
- rule based optimization
- new optimization rules can be added
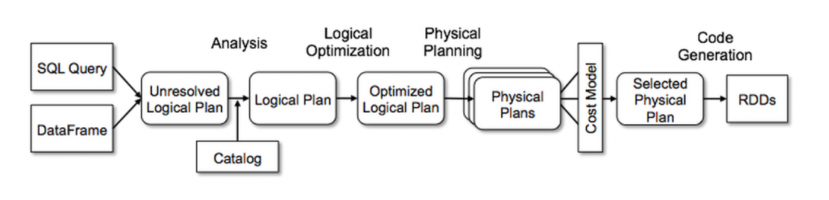
parsed logical plan
- unresolved
- our query is parsed and we get a parsed logical plan
- it checks for any of the syntax errors
resolved/analysed logical plan
- resolve the table name, column names etc.
- if column name or table name is not available then analysis exception is raised
optimized logical plan
- catalyst optimizer
- filter push down
- combining of filters
- combining of projections
- many such rules which are already in place
- we can add our own rules in the catalyst optimizer
physical plan
- creates mutiple physical plans like Sortaggregate, HashAggregate
- select the physical plan which is the most optimized one with minimum cost
- selected physical plan is converted to rdd code
connect external source
create dataframe by connectin to mysql table, requires jar mysql-connector-java.jar
spark-shell --driver-class-path /usr/share/java/mysql-connector-java.jar
val connection_url ="jdbc:mysql://servername/databasename"
val mysqlProperty = new java.util.Properties
mysqlProperty.setProperty("user","username")
mysqlProperty.setProperty("password","password")
val orderDF = spark.read.jdbc(connection_url,"tablename",mysqlProperty)orderDF.show()
Sources
- https://databricks.com/glossary/catalyst-optimizer
Comments