
hbase
rdbms properties
- structured
- random access
- low latency
- ACID
- Atomic: full transaction either completes or fail
- Consistency: updates should not violate constraints
- Isolation: multiple concurrent sessions can work on database in some sequence using locking
- Durability: data is stored and recoverable even after failure
limitations of hadoop
- unstructured data
- no random access
- high latency
- no ACID compliance
bigtable/hbase
bigtable paper is published by google, it is distributed storage system for structured data. hbase is implementation of the same.
hbase is distributed database management system on top of hadoop. So is:
- distributed
- scalable
- fault tolerant
hbase properties
- loose structured: as each row can can different number of columns
- low latency: uses row keys to fetch data
- random access: uses row keys to fetch data
- somewhat ACID: as it provides ACID at row level only, not if multiple rows are updated
It provides batch processing using mapreduce and real time processing using row keys.
storage in hbase
It stores data in columnar format as shown below.
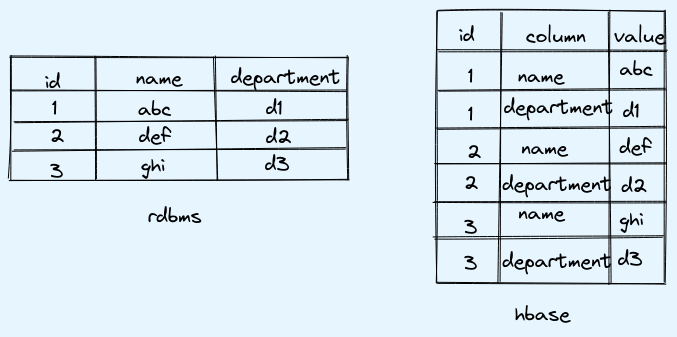
Advantages:
- sparse data: In case there is no data for some of the columns then those columns will be skipped while storing
- dynamic attributes: can have data with more or less columns
hbase vs rdbms
| rdbms | hbase |
| data is arranged in rows and columns | data is in columnar format |
| sql | nosql |
| supports groupping, joins, etc | supports only CRUD |
| normalized data to reduce redundancy | denaormalized (self contained) to reduce disk seek |
| ACID compliant | ACID compliant at row level |
| 2 dimiensional (row & column) | 4 dimensional |
4 dimensional model in hbase
- row key
- uniquely identifies row
- represented internally as byte array
- sorted in asc order
- column family
- all rows have same set of column family
- setup at definition
- can have different columns for different rows
- column
- exist in one of the column family
- can be dynamic
- timestamp
- used for versioning
- vaule for old version can also be accessed
Below shows all the four dimesnions and how data is stored. Like for col2 all the historic vaules will be stored with the timestamp and by default it gives latest but can be queried old data as well.
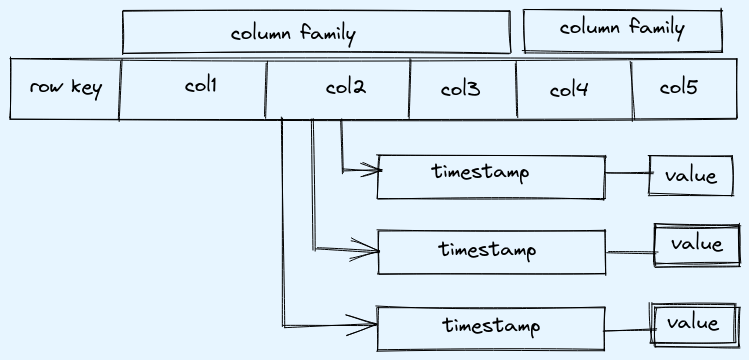
Note:
- all data is stored in byte array in form of bytes in hbase, there is no concept of data types in it
- row keys are stored in sorted asc order, so as binary search can be done to find value
- column families are fix and defined when creating table
- columns can be more or less
hbase architecture
hbase table is collection of rows and columns that are sorted based on row key. This table is distributed according to fix size, each portion of table is called region.
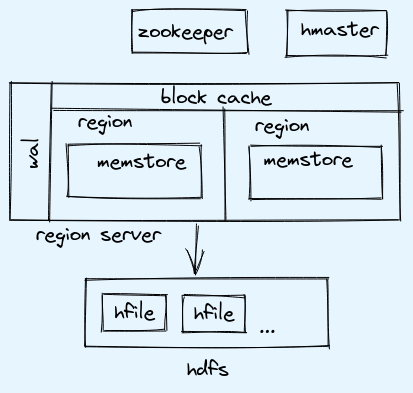
region:
- sorted data is stored based on row keys
- column families are stored in seperate files
- assume 1 million rows in table and we have 4 regions then .25 million will go in each region
region server:
- can have multiple region stored in one region server
- if 4 data nodes and typically 4 region server is good practice
- each region server contain wal, block cache
wal:
- write ahead log, also known as hlog
- in case of region server failure, and data is still in memstore. In order to prevent data loss, log is written to permanent store (hdfs)
block cache: whenever read is done data is cached in memory, so next read can be done directly by cache
memstore:
- every insert is appended in memstore, after threshold is reached then data is flushed to disk with a new file created and this new file is called hfile
- for each region there will be memstore per column family
zookeeper:
- it is cordinating service for various distributed system
- hold location for metatable
- every system send heartbeat
- metatable hold mapping of rowkey, region and region servers
- metatable is present on one of region server and zoopkeep knows which region server hold it.
- in case of hmaster failue, zookeeper assign other master as new master
- in case region server fails, zookeeper notify hmaster then hmaster reassigns regions of failed region server to other region server
hmaster:
- is master and region servers are slaves
- can have one or more master node but only one will be active at a time
- assign region servers
- in case of failure/load it will balance among region servers
- perform admin stuff like ddl (creating/deleting tables)
hfiles:
- stored in hdfs
- stores hbase table data as sorted key-value pairs
- immutable
- large in size depends on memstore flush size
- stores data as set of blocks, which helps reading particular block
- default block size 64KB
Example: consider hfile of 250MB and block size of 64KB, then just 64KB need to be scanned if we search for a particular row key, And also in that block, binary search is applied to get particular row as data is stored sorted.
metatable:
- stores location of regions along with region servers
- helps user identify the region server and its corresponding regions where specific range data is stored
- stored in one of region server and its location is stored in zookeeper
Note:
- wal and block cache is one per region server
- client intreacts directly with the region server to perform read/write operations
read/write operation
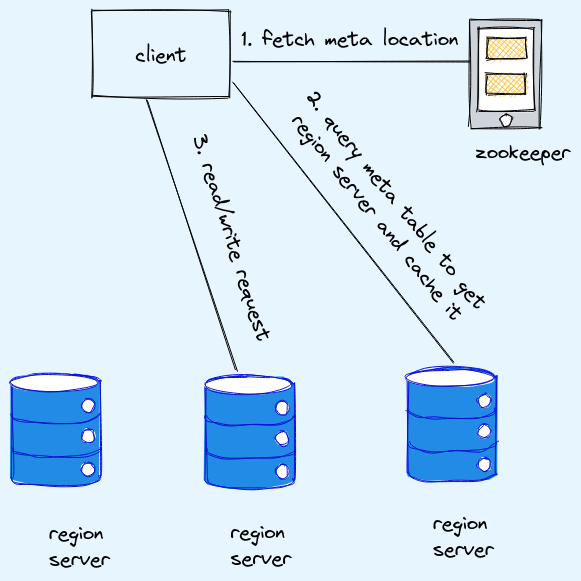
read
- region server checks the block cache.
- if not in block cache them memstore is checked
- if not in memstore then hfile
- in hfile particular block will be scanned based on row key and in order to find row key binary search is done in the block
write
- data is first written in wal
- then to memstore
- once memstore is filled, content is flushed to hdfs in new hfile
compaction
flush to hfile from memstore create multiple hfiles, especially on frequent write, which leads to slow read. To solve this we can use compactions:
minor: smaller hfiles are processed and rewritten into few larger files
major: all hfiles are picked and rewritten into single large hfile
Note: major compaction is more resource intensive
data update/delete
update:
- update is done based on timestamp
- versions are maintained
delete: delete is special type of update where vaules of deleted data is not deleted immediatly rather are marked by assigning tombstone marker. Request to read the deleted data then returns null because of tombstone marker which identifyies that data is deleted.
Reason for this is hfiles are immutable as these are hdfs files. All vaules with tombstone markers are deleted in next major compaction.
Note: querying hbase has different commands which are not like sql, apache phoenix provides sql like interface on top of hbase.
Comments