
file formats for big data
There are certain parameters to consider when chossing a file format.
- storage space consumption
- processing time
- io consumption
- read/write speed
- if data can be split in files
- schema evolution
- compression
- compatible with framework like hive/spark etc.
ways in which data can be stored
row based: write is simple but read will have to read full row even if subset of column is read.
column based: all columns values are stored together. Write will be slower comparatively. But read will be efficient. In this we can get good compression as well.
file formats
csv:
- all data stored as text so takes a lot of storage for example if column has integer value then that consumes more storage because its stored as text.
- processing will be slow as conversion need to be done.
- io will be slow as data storage is more so will do more io.
xml:
- semi structure
- all negative of csv applies here as well.
- these files can not split.
json:
- semi structure
- all negative of csv applies here as well.
avro:
- row based storage
- faster write as its row based
- slow read for subset of columns
- schema of file is stored in json
- data is self describing because schema is embeded as part of data
- actual data is in binary format
- general file format, programming language agnostic can used in many languages
- matuare in schema evolution
- serialization format
orc
- optimized row columnar
- write are not effecient
- effecient reads
- highly effecient in terms of storage
- compression (dictionary encoding, bit packing, delta encoding, run length encoding along with generalzed compression like snappy/gzip)
- predicate pushdown
- best fit for hive, supports all datatypes including complex used in hive
- initially specially designed for hive
- supports schema evolution, not matuare as avro
- self describing, as stores metadata(using protocol buffers) in the end of file itself
parquet
- column based storage
- writes are not effecient
- effecient reads
- shares many design patterns as of orc, but more general purpose
- very good in handling nested data
- compression is effecient
- self describing, as stores metadata in the end of file itself
- supports schema evolution adding/removing columns in the end
orc storage internals
Data is stored as shown in the below image. Mainly it has below sections.
Header
It contains text ORC
Body
In it data is divided in multiple stripes (default size is 250MB) and each stripe has-
- Index data: max, min, count of each column in every row group in the stripe
- Row data: data is broken in row groups each row group has 10000 rows by default
- Stripe footer: stores encoding used
Footer
- File footer: contains metadata at file and stripe level like max, min, count.
- Postscript: stores which compression is used like snappy/gzip, postscipt is never compressed
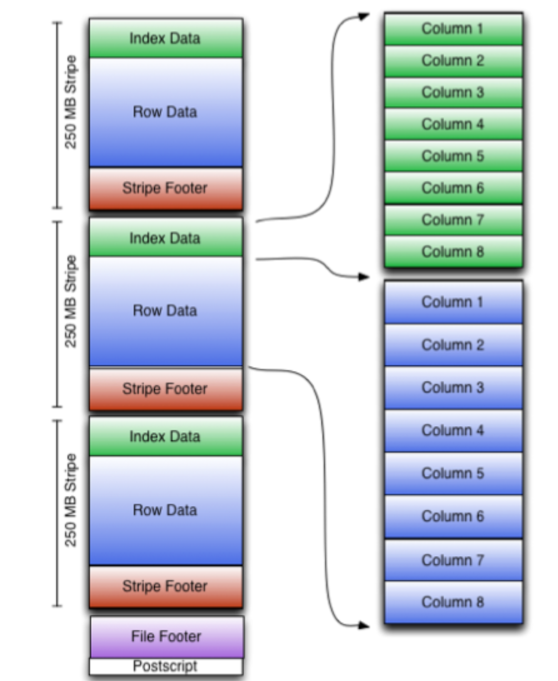
Note: Flow is like header is read to identify orc file and then postscript is read to get compression used and then file footer then stripes and row data.
parquet storage internals
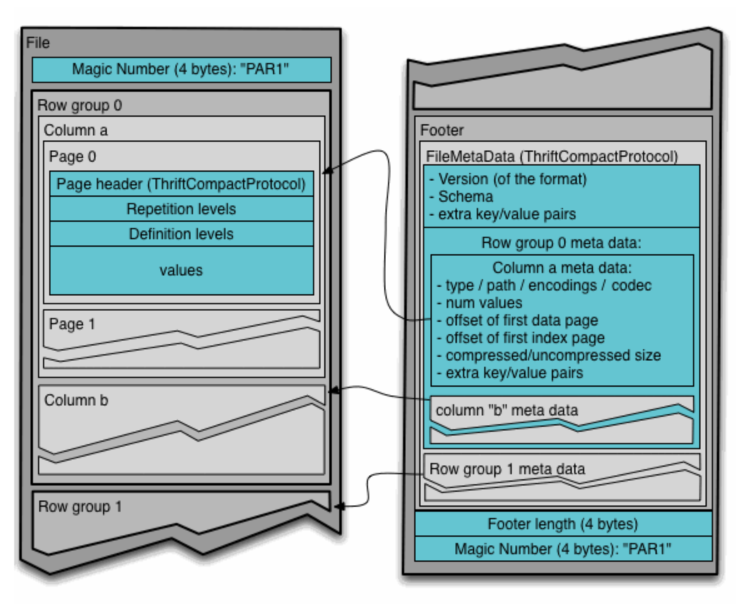
Data is stored as shown in the below image. Mainly it has below sections.
Header
It contains text PAR1
Row group
In it data is divided in column chunks which is further divided in pages.
Footer
- File metadata: encoding, schema, etc.
- Lenght of file metadata
- Magic number
PAR1
compression
dictionary encoding
Suppose we have sales data where product name column, customer name column exist then that will have same values for a lot of rows. For this dictonary encoding helps by having dictionary where distinct vaules are stored and then referenced.
bit packing
Suppose we have int column in the dateset, for that column if the vaule is less than bit packing can help by representing same number with less bits.
delta encoding
Suppose we have timestamp column in dataset then first timestamp is stored and then for next column vaule it can store difference only. Example vaule is 123456 and next vaule is 123457 then base vaule stored can be 123456 and next value 1.
run length encoding
Suppose we have column in dataset which has value dddddfffgg then the vaule stored is d5f3g2
Note:
- serialization is converting data into a form which can be easily transferred over the network and stored in file system.
- there is no other file format better than avro for schema evolution.
- avro can be best fit for landing raw data in data lake.
- in avro, orc, parquet any compression can be used, compression code is stored in metadata, so reader can get to know compression code from metadata.
Sources
- https://orc.apache.org/specification/ORCv2/
- https://parquet.apache.org/documentation/latest/
Comments